- Published on
Learned Motion Matching
- Authors

- Name
- Vincent Hu
Learned Motion Matching: A Deep Learning Approach to Character Animation
Introduction
Learned Motion Matching is a cutting-edge technique that combines traditional motion matching algorithms with deep learning to create smooth, responsive character animations in real-time. This project implements the framework described in the original paper by Daniel Holden, extending it with an alternative diffusion-based projector network for improved motion quality.
Motion matching is a data-driven animation technique that searches through a database of motion clips to find the best matching frame based on current character state and desired goals. By incorporating neural networks, learned motion matching compresses the motion database into a compact latent space, enabling faster searches and more natural transitions between animation frames.
The Problem
Traditional animation systems face several challenges:
- Storage Overhead: Large motion databases require significant memory
- Search Complexity: Finding the best matching frame can be computationally expensive
- Transition Quality: Blending between different motion clips can produce artifacts
- Responsiveness: Real-time applications need fast, smooth animations
Learned Motion Matching addresses these issues by using neural networks to compress motion data and predict optimal transitions, resulting in more efficient and higher-quality animations.
Architecture Overview
The Learned Motion Matching framework consists of three main neural network components:
1. Decompressor Network
The decompressor is responsible for reconstructing full character poses from compressed feature vectors. It takes a feature vector (representing the motion state) and latent variables as input, and outputs bone positions, rotations, velocities, and other animation data.
- Architecture: 2-layer fully connected network with 512 hidden units
- Input: Feature vector + Latent variables (32 dimensions)
- Output: Complete character pose data
2. Stepper Network
The stepper predicts how the character's state will evolve over time. It takes the current feature vector and latent variables, and predicts their velocities for the next frame.
- Architecture: 3-layer fully connected network with 512 hidden units
- Input: Feature vector + Latent variables
- Output: Feature velocity + Latent variable velocity
3. Projector Network
The projector maps query feature vectors (representing desired goals or constraints) to the latent space, enabling the system to find matching frames that satisfy specific requirements.
Two implementations are provided:
Original Projector (Feed-forward)
- Architecture: 5-layer fully connected network with 512 hidden units
- Input: Query feature vector
- Output: Projected features + Projected latent variables
Diffusion-based Projector (Alternative)
- Architecture: U-Net style architecture with sinusoidal time embeddings
- Advantages: Potentially better projection quality and smoother transitions
- Compatibility: Fully compatible with the original C++ framework
Implementation Details
Technology Stack
- C++: Core framework using raylib for visualization
- Python: Training scripts using PyTorch
- WebAssembly: Browser-based demo compiled with Emscripten
- Neural Networks: Custom implementations of compressor, decompressor, stepper, and projector networks
Training Pipeline
The training process follows a specific order:
Decompressor Training (must be done first):
- Uses
database.binandfeatures.binfrom the motion database - Produces
decompressor.binandlatent.bin - Generates visualization images and BVH files for validation
- Uses
Stepper and Projector Training (can be done in parallel):
- Trains the stepper network to predict state evolution
- Trains either the original or diffusion-based projector network
- Outputs trained model files compatible with the C++ framework
Training Parameters
- Iterations: 500,000
- Batch Size: 32
- Learning Rate: 0.001
- Optimizer: AdamW (amsgrad=True, weight_decay=0.001)
- Learning Rate Scheduler: ExponentialLR (gamma=0.99)
Key Features
Real-time Performance
The compressed representation allows for fast searches through the motion database, enabling real-time character animation even with large motion datasets.
Smooth Transitions
Neural networks learn optimal blending between motion frames, producing smoother and more natural transitions than traditional interpolation methods.
Interactive Web Demo
A fully functional web demo runs entirely in the browser using WebAssembly, allowing users to interact with the system using gamepad controllers.
Diffusion-based Enhancement
The alternative diffusion-based projector network provides an experimental approach that may offer improved projection quality and motion smoothness.
Results
The implementation successfully reproduces the original Learned Motion Matching framework, with results demonstrating:
- Efficient Compression: Motion database compressed into a compact latent representation
- Natural Animations: Smooth character movements for walking and running motions
- Real-time Responsiveness: Fast frame matching suitable for interactive applications
- Compatibility: Full compatibility with the original C++ visualization framework
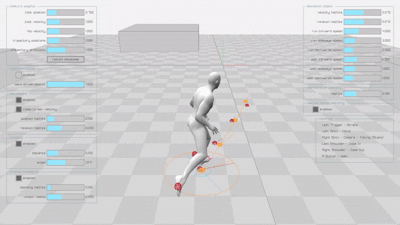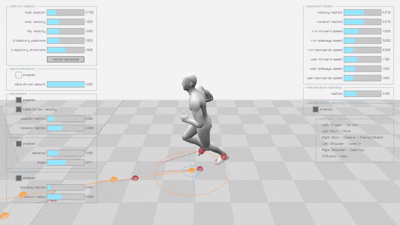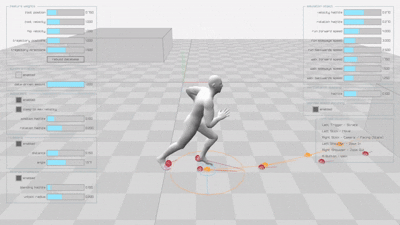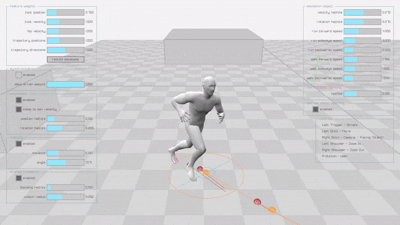
Learned Motion Matching (LMM)
The original implementation produces smooth, natural animations for both walking and running motions:
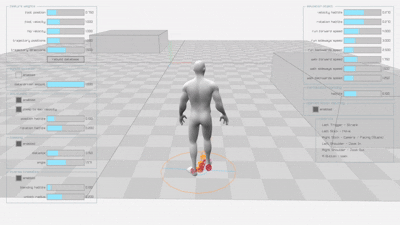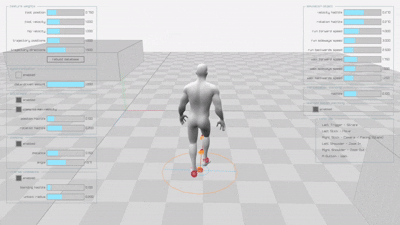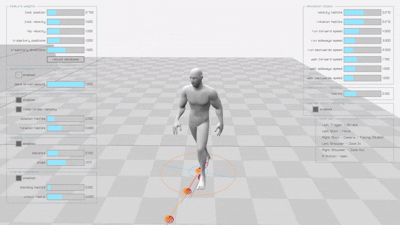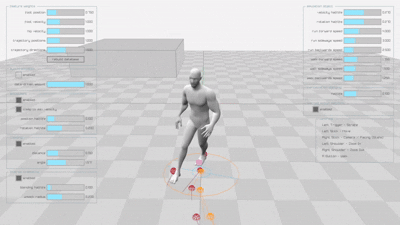

Diffusion-based Learned Motion Matching (DLMM)
The alternative diffusion-based projector network provides enhanced motion quality:

Technical Highlights
Database Compression
The system compresses the full motion database (bone positions, rotations, velocities) into a compact feature space, dramatically reducing memory requirements while maintaining animation quality.
Learned Features
The decompressor network learns to reconstruct full character poses from compressed representations, enabling efficient storage and retrieval of animation data.
Projection Quality
Both the original feed-forward projector and the diffusion-based alternative successfully map query features to the latent space, enabling accurate motion matching.
Limitations and Future Work
While the implementation successfully reproduces the original framework, there are areas for potential improvement:
- Processing Speed: Further optimizations could improve real-time performance
- Motion Variety: Expanding the motion database could support more diverse animations
- Diffusion Refinement: The diffusion-based projector could benefit from additional training and tuning
Conclusion
This implementation of Learned Motion Matching demonstrates the power of combining traditional animation techniques with modern deep learning approaches. By compressing motion data into a learned latent space, the system achieves efficient, high-quality character animation suitable for real-time applications.
The project includes both the original feed-forward projector and an experimental diffusion-based alternative, providing flexibility for different use cases and research directions. The web-based demo showcases the system's capabilities in an accessible, interactive format.